実行例
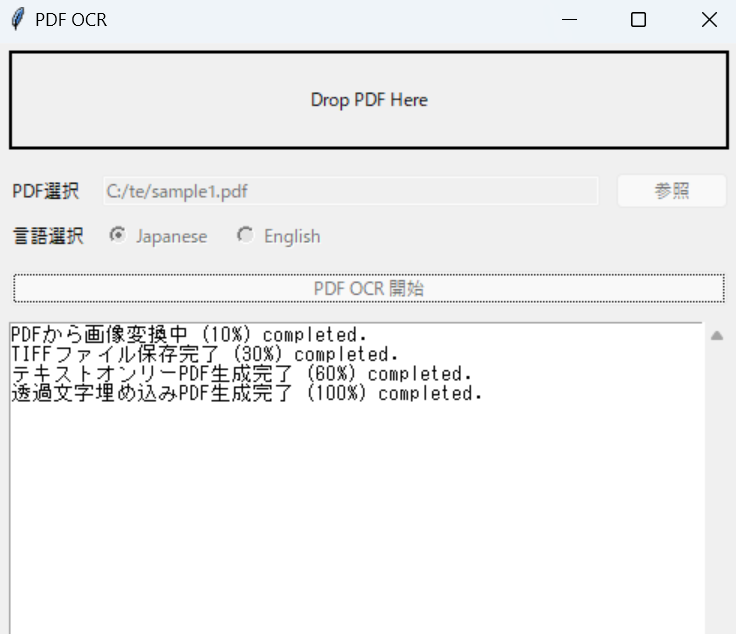
概要
このブログでは、Pythonを使用してPDFファイルからテキストを抽出し、テキストをPDFに埋め込むための簡単なアプリケーションの作成方法を紹介します。このツールは、ドラッグアンドドロップインターフェースを備え、任意のPDFファイルからテキストを読み取って新しいテキスト埋め込みPDFを生成します。
なお、今回のツールは下記サイトを参考に作成してみました。ご参照ください。
https://qiita.com/takafi/items/67cb5be4e0eed23be606
使用例
このプログラムは、ビジネスドキュメントや学術資料など、さまざまなPDFファイルのテキストを抽出して編集可能な形式に変換するのに役立ちます。生成されたテキストは、編集やデータ解析のためにテーブルデータとしてさらに抽出されることが可能です。
必要なPythonライブラリとインストール方法
このプロジェクトには以下のライブラリが必要です。
- pdf2image: PDFから画像への変換を行います。
- pytesseract: OCRエンジンを利用して画像からテキストを抽出します。
- tkinterdnd2: ドラッグアンドドロップ機能をGUIに追加します。
- Pillow: 画像処理を行います。
これらのライブラリをインストールするには、以下のコマンドを実行してください:
pip install pdf2image pytesseract tkinterdnd2 Pillow
外部ツールのインストールと設定
以下の3つのツールも必要です:
- Tesseract OCR:オープンソースの光学文字認識(OCR)エンジン。画像からテキストを抽出することができる。
- QPDF:PDFファイルを操作するためのコマンドラインツール。PDFの構造を変更したり、新しいPDFを生成したりすることができる。
- Poppler:PDF文書を扱うためのライブラリで、特にPDFから高品質の画像を生成するのに使用される。
pdf2imageライブラリと共に利用されることが多い。
各外部ツールのインストール方法 (Windowsの場合)
Tesseract OCR
- TesseractのGitHubページからインストーラー(tesseract-ocr-w64-setup-x.x.x....exe)をダウンロードし、指示に従ってインストール進めてください。
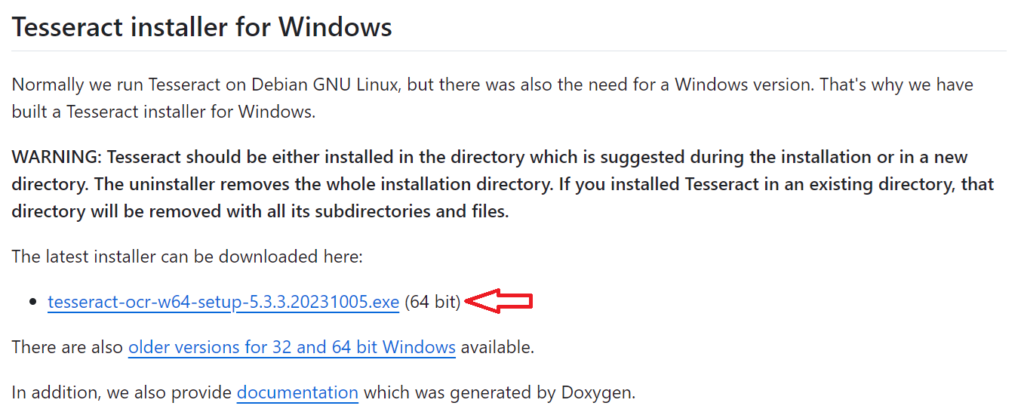
2-1.インストールする際、Install for anyone using this computerを選択することをお勧めします。
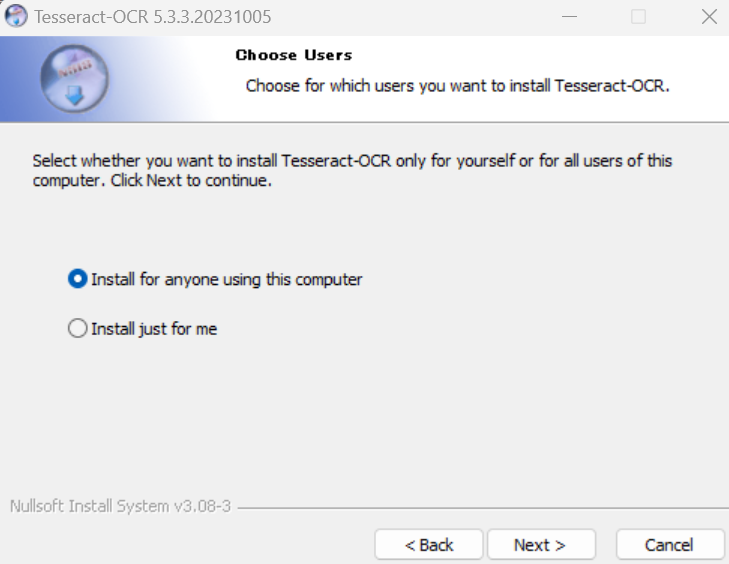
2-2.Select components to installでは、Additional script data (download)とAdditional language data (download)の中の日本語に関するデータにチェックを入れてください。
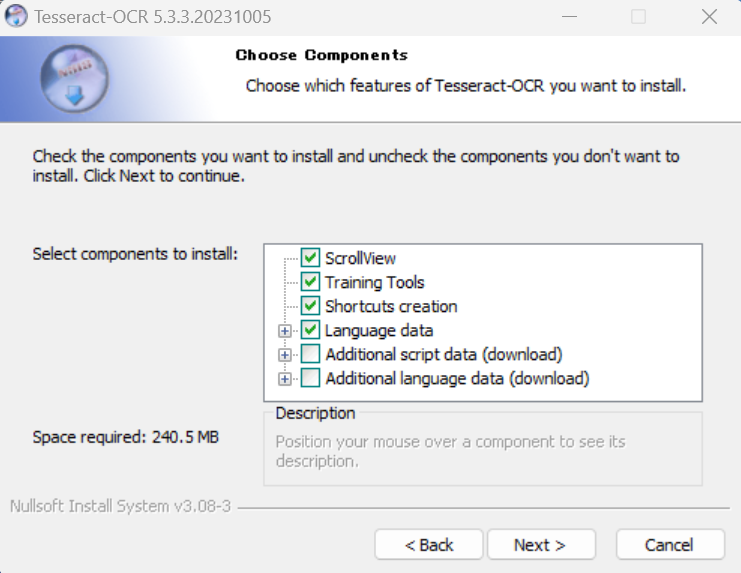
2-2-1.Additional script data (download)では[Japanese script]と[Japanese vertical script]を選択してください。
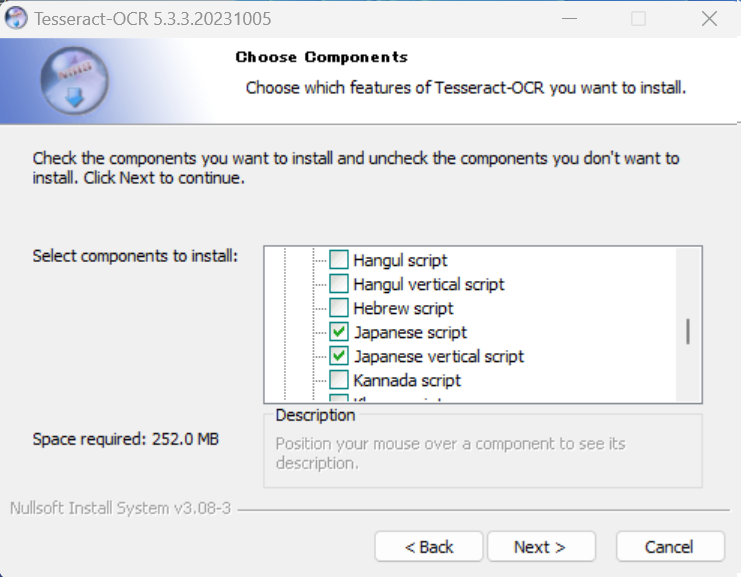
2-2-2.Additional language data (download)では[Japanese]と[Japanese (vertical)]を選択してください。これでOCRで日本語を認識するようになります。
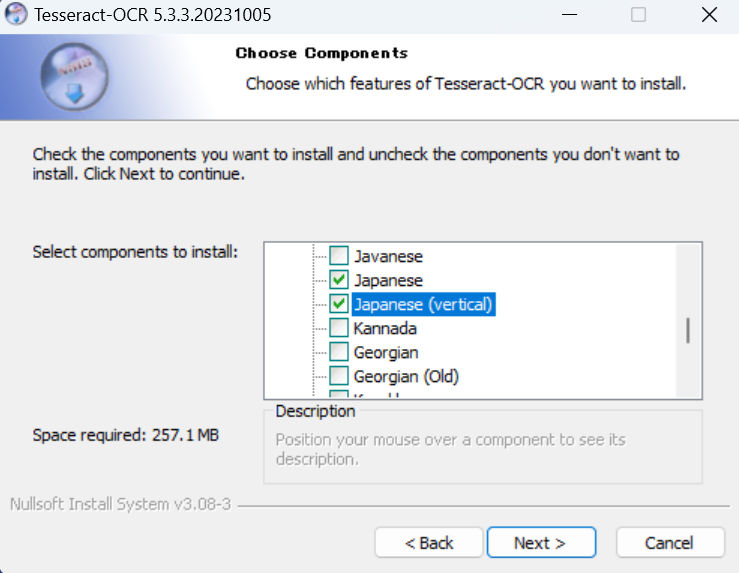
※次の項目でPATHの設定を説明します。このツールを使用するのに必須です。
QPDF
1.QPDFの公式サイトのLatest Releaseをクリック。

2.qpdf-xx.x.x-msvc64.zipをダウンロードし、インストールしてください。
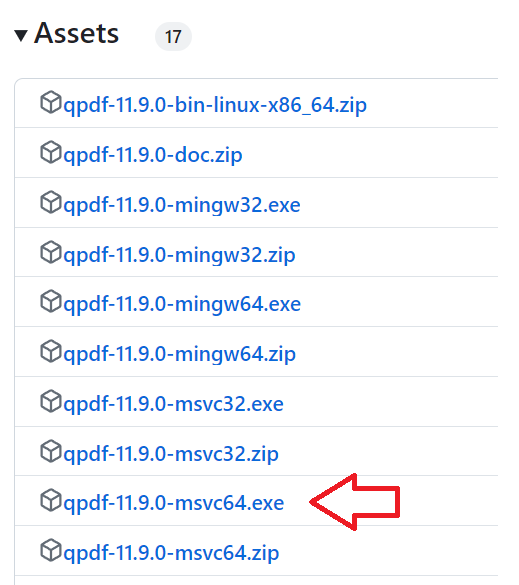
※次の項目でPATHの設定を説明します。このツールを使用するのに必須です。
poppler
1.Windows用にコンパイルしてくれているサイトからRelease-xx.xx.x-x.zipをダウンロードし、回答
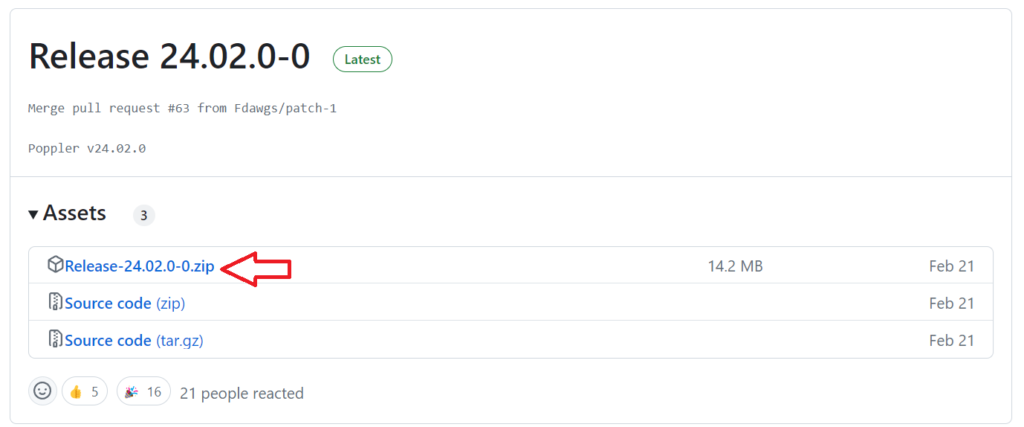
2.zipフォルダを解凍すると以下のようなフォルダ構成ができるので、以下の手順を配置します。
- [share]フォルダ内の[poppler]フォルダを、[Library]フォルダ内の[share]フォルダ内に移動
- [Library]フォルダを[poppler]に変更して、任意の場所に移動させる(Cドライブ直下やProgram Filesなどがおすすめ)
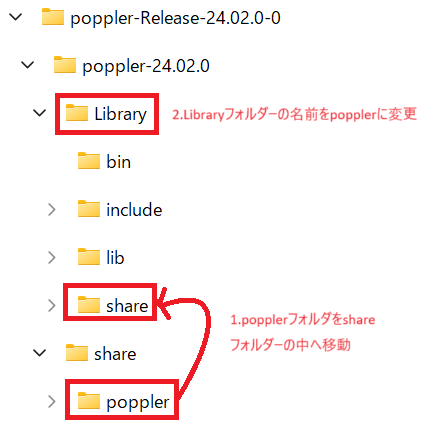
3.結果として下記のようになるようなフォルダ構成になります。
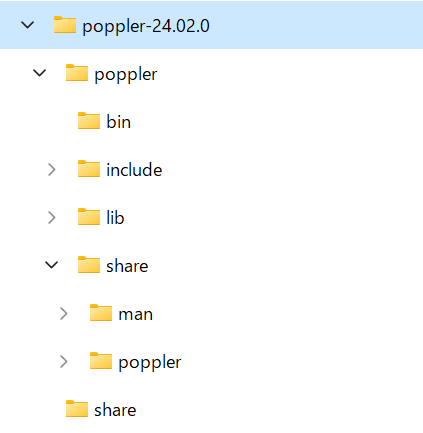
※次の項目でPATHの設定を説明します。このツールを使用するのに必須です。
各外部ツールのPath環境変数を設定/編集
外部ツールであるTesseract OCR、poppler、QPDFをWindowsで使用する際はPath環境変数を設定をし、binフォルダへパスを通す必要があります。Pathの通し方は下記になります。
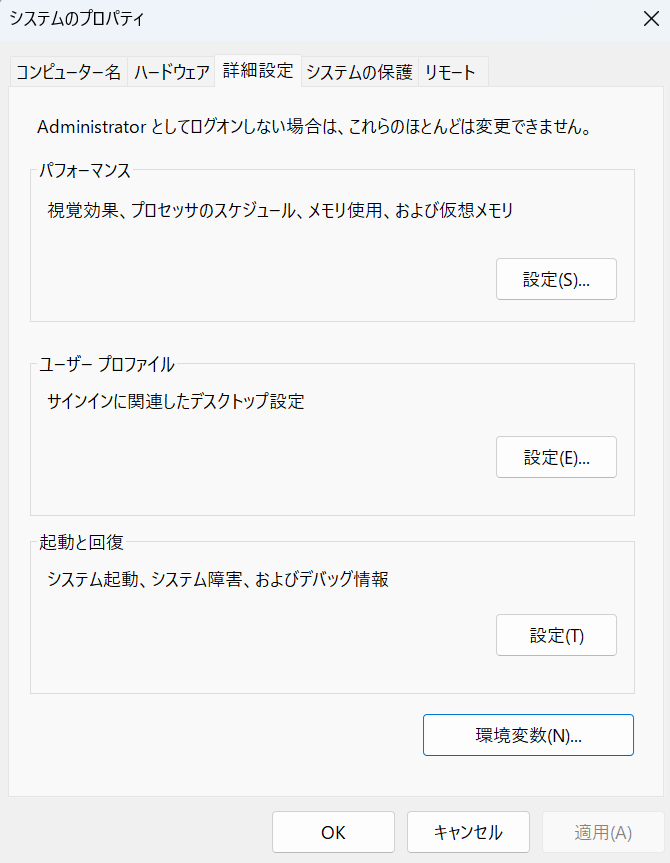
1.「システム環境変数の編集」で検索し、「環境変数」をクリック
2.「システム環境変数」からpathを選択し、「編集」をクリック
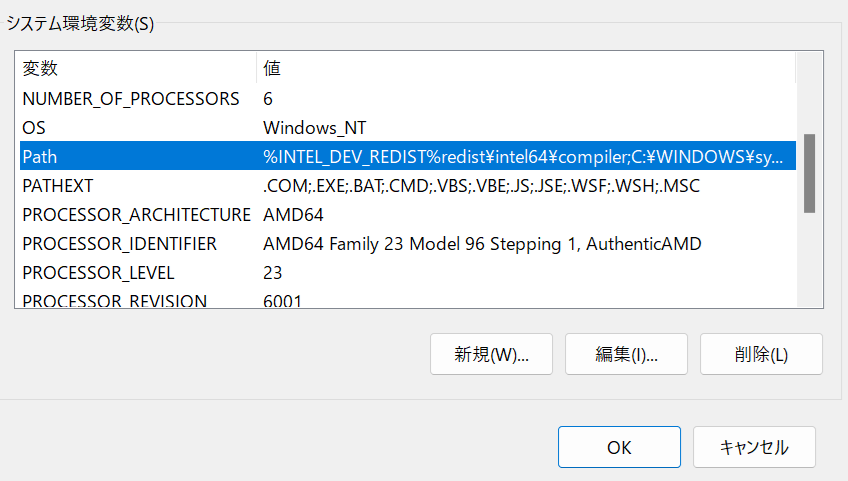
3.「新規」をクリックし、qpdf、popplerはそれぞれのbinフォルダに、Tesseract OCRはTesseract OCRフォルダにpathを設定します。(画像は一例です。実際に保存した場所のpathを入力してください)
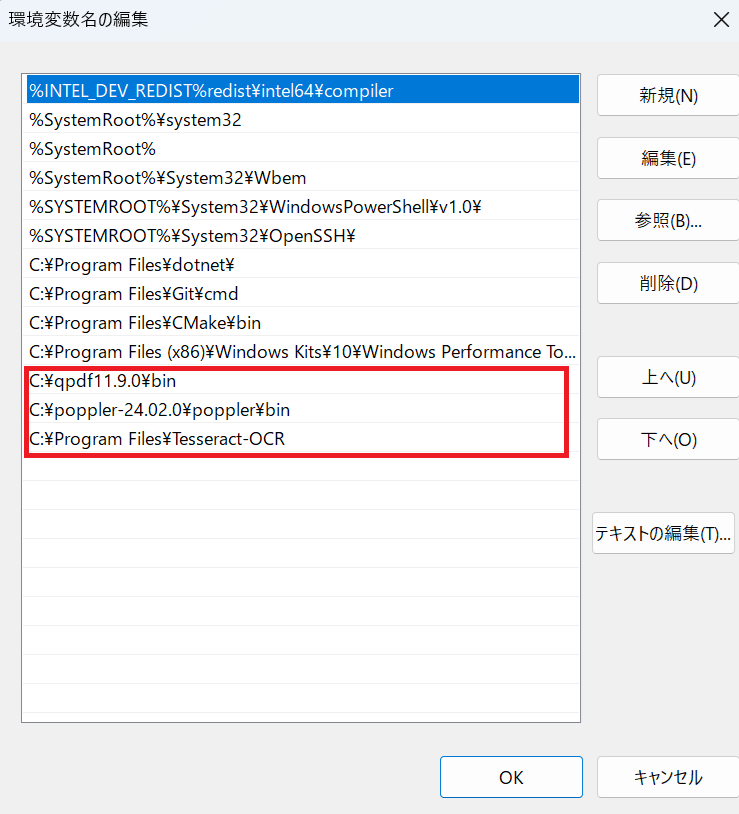
4.PCを再起動すると準備完了です。※再起動しないとインストールしたにも関わらず、「pathが見当たらない」旨が表示され、プログラムが実行できないことがあります。
各外部ツールのPathの設定の確認方法
PATHが通っているかはコマンドプロンプトに下記内容を入力してエラーが出ないことを確認してください。
Tesseract OCR
tesseract --help
QPDF
qpdf --help
poppler
pdftocairo --help
インストールが完了して、パスが通っていれば、それぞれ以下のコマンドでヘルプが参照できます。
使用手順
- 上記のライブラリをインストールします。
- 提供されたPythonスクリプトを任意のテキストエディタにコピーして
.pyファイルとして保存します。 - スクリプトを実行し、PDFファイルをアプリケーションウィンドウにドラッグアンドドロップします。
- 「PDF OCR 開始」ボタンをクリックして、テキストの抽出とPDFの生成を開始します。
注意点
- プログラムは
tesseractおよびqpdfがシステムにインストールされている必要があります。 - 大きなPDFファイルや高解像度の画像を含むファイルを処理する場合、処理時間が長くなる可能性があります。
pdf2image, pytesseract, tkinterdnd2,がインストールされ、それぞれのpathが通っていることを確認してください。Pillow,Tesseract OCR, qpdf, poppler の7つのプログラムがインストールされていることを確認してください。特にTesseract OCR, qpdf, poppler
プログラム
import os
import sys
import time
import threading
import subprocess
from pdf2image import convert_from_path
import pytesseract
from tkinterdnd2 import DND_FILES, TkinterDnD
import tkinter as tk
from tkinter import ttk
from tkinter import messagebox
from tkinter import filedialog
from tkinter import scrolledtext
class Application(tk.Frame):
def __init__(self, master=None):
super().__init__(master)
self.master.geometry('500x400')
self.master.title('PDF OCR')
self.master.resizable(width=False, height=True)
self.master.grid_rowconfigure(5, weight=1)
self.master.grid_columnconfigure(2, weight=1)
self.progress_var = tk.DoubleVar() # Variable to track the progress
self.drop_frame = tk.Label(self.master, text="Drop PDF Here", relief="solid", width=60, height=4)
self.drop_frame.grid(row=0, column=0, columnspan=4, padx=10, pady=5, sticky='ew')
self.drop_frame.drop_target_register(DND_FILES)
self.drop_frame.dnd_bind('<<Drop>>', self.drop)
self.DirLabel = ttk.Label(self.master, text='PDF選択')
self.DirLabel.grid(row=1, column=0, padx=(10, 0), pady=(10, 5), sticky='ew')
self.entry = tk.StringVar()
self.DirEntry = ttk.Entry(self.master, textvariable=self.entry, width=50)
self.DirEntry.grid(row=1, column=1, columnspan=2, padx=10, pady=(10, 5), sticky='ew')
self.DirButton = ttk.Button(self.master, text='参照', command=self.dialog_open)
self.DirButton.grid(row=1, column=3, padx=(0, 10), pady=(10, 5), sticky='ew')
self.radio = tk.StringVar(value='jpn')
self.LangLabel = ttk.Label(self.master, text='言語選択')
self.LangLabel.grid(row=2, column=0, padx=(10, 0), pady=(0, 10), sticky='ew')
self.radio_jpn = tk.Radiobutton(self.master, text='Japanese', value='jpn', variable=self.radio)
self.radio_jpn.grid(row=2, column=1, padx=(10, 0), pady=(0, 10), sticky='w')
self.radio_eng = tk.Radiobutton(self.master, text='English', value='eng', variable=self.radio)
self.radio_eng.grid(row=2, column=2, padx=(10, 0), pady=(0, 10), sticky='w')
self.button = ttk.Button(self.master, text='PDF OCR 開始', command=self.callback, width=40)
self.button.grid(row=3, column=0, columnspan=4, padx=10, pady=(0, 10), sticky='ew')
self.scrolledText = scrolledtext.ScrolledText(self.master)
self.scrolledText.grid(row=4, column=0, columnspan=4, padx=10, pady=(0, 10), sticky='nsew')
self.scrolledText.tag_config('error', foreground="red")
# Progress bar
self.progress_bar = ttk.Progressbar(self.master, variable=self.progress_var, maximum=100, length=480)
self.progress_bar.grid(row=5, column=0, columnspan=4, padx=10, pady=(0, 10), sticky='ew')
sys.stdout.write = self.output_print
sys.stderr.write = self.output_error
self.is_external_software_installed()
def update_progress(self, value, msg=""):
self.progress_var.set(value)
self.scrolledText.insert(tk.END, f"{msg} ({value}%) completed.\n")
self.master.update_idletasks() # Force an update of the GUI
def drop(self, event):
files = self.master.tk.splitlist(event.data)
if files:
filepath = files[0]
self.entry.set(filepath)
def dialog_open(self):
file_path = filedialog.askopenfilename(title="Open PDF File", filetypes=[("PDF files", "*.pdf")], initialdir=os.path.expanduser("~"))
if file_path:
self.entry.set(file_path)
def output_print(self, msg):
self.scrolledText.insert(tk.END, msg)
self.scrolledText.see("end")
def output_error(self, msg):
self.scrolledText.insert(tk.END, msg, 'error')
self.scrolledText.see("end")
def is_external_software_installed(self):
check_lists = [('qpdf', 'QPDF'), ('tesseract', 'Tesseract OCR'), ('pdftocairo', 'poppler')]
not_installed = []
for cmd, software in check_lists:
try:
subprocess.Popen(f'{cmd} --help', stdout=subprocess.PIPE, stderr=subprocess.PIPE)
except FileNotFoundError:
not_installed.append(software)
if not_installed:
messagebox.showerror('Error', f'{", ".join(not_installed)}がインストールされていません')
self.widgets_disabled()
def callback(self):
self.widgets_disabled()
threading.Thread(target=self.main).start()
def main(self):
pdf_path = self.entry.get()
if not pdf_path:
messagebox.showerror('Error', 'ファイルパスが入力されていません')
self.widgets_enabled()
return
save_dir = filedialog.askdirectory()
if not save_dir:
messagebox.showerror('Error', '保存先ディレクトリが指定されていません')
self.widgets_enabled()
return
threading.Thread(target=lambda: self.pdfocr_process(pdf_path, save_dir)).start()
def pdfocr_process(self, pdf_path, save_dir):
pdf_file = os.path.basename(pdf_path)
pdf_base = os.path.splitext(pdf_file)[0]
tmp_path = os.path.join(save_dir, f'{pdf_base}_tmp.tif')
ocr_file = os.path.join(save_dir, f'{pdf_base}_ocr.pdf')
self.update_progress(10, "PDFから画像変換中")
images = convert_from_path(pdf_path, 300)
images[0].save(tmp_path, "TIFF", compression="tiff_deflate", save_all=True, append_images=images[1:])
self.update_progress(30, "TIFFファイル保存完了")
lang = self.radio.get()
cmd = f'tesseract "{tmp_path}" "{tmp_path[:-4]}_txtonly" -l {lang} pdf'
subprocess.run(cmd, shell=True, check=True)
self.update_progress(60, "テキストオンリーPDF生成完了")
cmd = f'qpdf --overlay "{tmp_path[:-4]}_txtonly.pdf" -- "{pdf_path}" "{ocr_file}"'
subprocess.run(cmd, shell=True, check=True)
self.update_progress(100, "透過文字埋め込みPDF生成完了")
messagebox.showinfo('Success', f'OCR処理が完了しました。ファイルは {ocr_file} に保存されました。')
def widgets_disabled(self):
self.button.state(["disabled"])
self.DirButton.state(["disabled"])
self.DirEntry.state(["disabled"])
self.radio_jpn.configure(state=tk.DISABLED)
self.radio_eng.configure(state=tk.DISABLED)
def widgets_enabled(self):
self.button.state(["!disabled"])
self.DirButton.state(["!disabled"])
self.DirEntry.state(["!disabled"])
self.radio_jpn.configure(state=tk.NORMAL)
self.radio_eng.configure(state=tk.NORMAL)
if __name__ == '__main__':
root = TkinterDnD.Tk()
app = Application(master=root)
app.mainloop()
あるいは、下のテキストファイルをダウンロードし、「.txt」を「.py」に変えることでそのまま使えます。
まとめ
このブログで紹介したツールを使用すると、PDFからテキストを効率的に抽出し、それをさらに活用することができます。ビジネスや研究でPDF文書を頻繁に扱う方には特にお勧めのツールです。難易度は少々高めですが、使えるようになると便利なので、ぜひチャレンジしてみてください。